Stay ahead with actionable finance strategies, tips, news, and trends.
Redes neuronales para principiantes Pt.1
El mundo del desarrollo de software está experimentando algunos cambios fundamentales con el resurgimiento de diversas técnicas de IA. El impacto más significativo ha llegado en forma de aprendizaje a
abril 9, 2019- Share:
-

-

-

-

El mundo del desarrollo de software está experimentando algunos cambios fundamentales con el resurgimiento de diversas técnicas de IA. El impacto más significativo ha llegado en forma de aprendizaje automático y, más concretamente, de un subconjunto del aprendizaje automático denominado aprendizaje profundo. El aprendizaje automático es simplemente una forma de IA que permite a un sistema "aprender" o ser "entrenado" a partir de datos en lugar de mediante programación explícita. Es importante señalar que estas técnicas no son nuevas. El término IA fue acuñado por primera vez por John McCarthy en 1956 y se define como la capacidad de una máquina para imitar el comportamiento humano inteligente. Esto no debe confundirse con que una máquina tenga inteligencia real o sea capaz de imitar genéricamente a un ser humano real. Los sistemas de IA están diseñados para imitar capacidades humanas específicas. Por ejemplo: entender el lenguaje, resolver problemas específicos, reconocer sonidos/imágenes y categorizarlos, hacer predicciones, etc. Todas ellas son capacidades muy potentes, pero no reflejan la inteligencia "real".
A lo largo de los años se han investigado distintos tipos de inteligencia artificial, pero la mayoría se han quedado en el camino, mientras que el aprendizaje automático ha encontrado su renacimiento. En los años 90, las dos subcategorías de IA más investigadas eran el ML y los sistemas expertos. Los sistemas expertos son una técnica mediante la cual se programa un sistema con un conjunto de reglas en lugar de codificarlo explícitamente. Las reglas se procesaban mediante un "motor de reglas/inferencia" y podían llegar a manejar decenas de miles de eventos por segundo incluso en un hardware modesto. El problema era que las reglas tenían que ser definidas por expertos en la materia y estaban limitadas por la capacidad de los expertos para imaginar todas las situaciones posibles. En realidad, esto no es IA, sino una aproximación a ella.
Por otro lado, el aprendizaje automático es una técnica en la que el software (modelo) aprende de los datos en lugar de ser creado/codificado o definido por los desarrolladores de software. La técnica específica de ML que estoy describiendo en este documento se conoce como Aprendizaje Profundo o Redes Neuronales. Quiero señalar que esta técnica NO es nueva y fue desarrollada originalmente en los años 60, 70 y 80. De hecho, el avance que hizo utilizables las redes neuronales se llamó back propagation y se descubrió/publicó en 1986. Desgraciadamente, aunque las técnicas fundamentales para implementar redes neuronales se conocían bien, no eran realmente útiles por aquel entonces debido a los enormes recursos de procesamiento y al tamaño de los conjuntos de datos necesarios para entrenar las redes. La única solución comercial que conozco era un producto de Computer Associates de los años 90 llamado Neugents (parte de su suite de gestión de sistemas). Las redes neuronales fueron abandonadas por el sector comercial y la mayor parte del mundo académico, y sólo unas pocas universidades siguen investigando en este campo, principalmente aquí en Canadá.
Volvamos a las redes neuronales, que en realidad no son nada complicadas.
Empezando por lo básico, una red neuronal es un conjunto de neuronas unidas en capas en cascada. La red comienza con una capa de entrada, pasa por capas ocultas y los resultados pasan finalmente por la capa de salida. Antes de entrar en detalles sobre esta estructura, tenemos que empezar por lo que se entiende por neurona (no nos referimos a una célula viva real).
Una neurona es un elemento de cálculo que recibe varias entradas y calcula una única salida. He aquí un ejemplo sencillo:
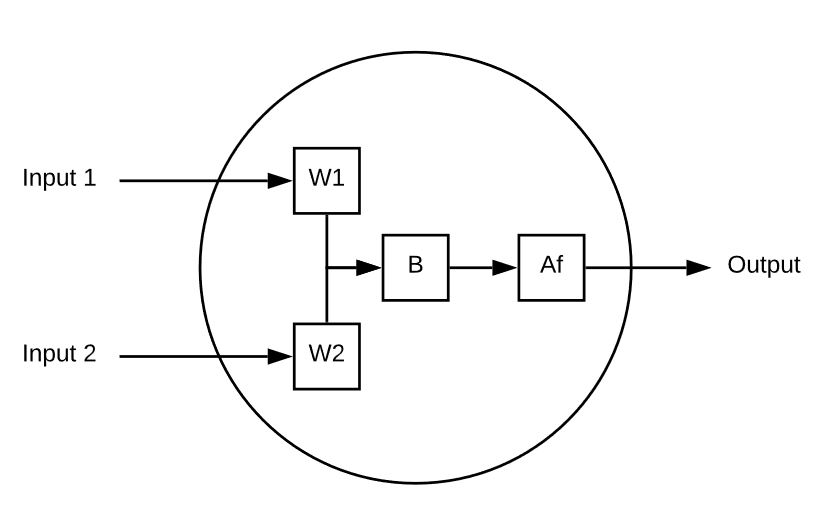 Esta neurona tiene 2 entradas.
Cada entrada se multiplica por el peso.
A continuación se suman las entradas ponderadas y se les añade un valor de sesgo.
Por último, el valor sin límites se pasa por una función de activación (sigmoidea, por ejemplo) para reducirlo a un rango predecible (de 0 a 1, por ejemplo).
He aquí un ejemplo de una neurona en acción:
Entrada 1 = 5, Entrada 2 = 8, W1 = 1 y W2 = .5, finalmente nuestro Bias es 3
Nuestra salida es la siguiente
Af( ( 5 * 1 ) + ( 8 * .5 ) + 3 )
Af( 12 ) = 0.999
Intentémoslo de nuevo con un conjunto diferente de entradas, pesos y sesgo:
Entrada 1 =-10, Entrada 2 = 10, W1 = 0,2, W2 = 0,1, Sesgo = 0,5
Salida = Af( (-10 + 0.2) + ( 2 X 0.1) + 0.5)
Salida = Af( -8.1 ) = 3.034
Una sola neurona por sí sola es esencialmente inútil aparte de como un ejercicio matemático interesante, pero si ponemos varias neuronas juntas en capas podemos tener una red neuronal en la forma de:
Esta neurona tiene 2 entradas.
Cada entrada se multiplica por el peso.
A continuación se suman las entradas ponderadas y se les añade un valor de sesgo.
Por último, el valor sin límites se pasa por una función de activación (sigmoidea, por ejemplo) para reducirlo a un rango predecible (de 0 a 1, por ejemplo).
He aquí un ejemplo de una neurona en acción:
Entrada 1 = 5, Entrada 2 = 8, W1 = 1 y W2 = .5, finalmente nuestro Bias es 3
Nuestra salida es la siguiente
Af( ( 5 * 1 ) + ( 8 * .5 ) + 3 )
Af( 12 ) = 0.999
Intentémoslo de nuevo con un conjunto diferente de entradas, pesos y sesgo:
Entrada 1 =-10, Entrada 2 = 10, W1 = 0,2, W2 = 0,1, Sesgo = 0,5
Salida = Af( (-10 + 0.2) + ( 2 X 0.1) + 0.5)
Salida = Af( -8.1 ) = 3.034
Una sola neurona por sí sola es esencialmente inútil aparte de como un ejercicio matemático interesante, pero si ponemos varias neuronas juntas en capas podemos tener una red neuronal en la forma de:
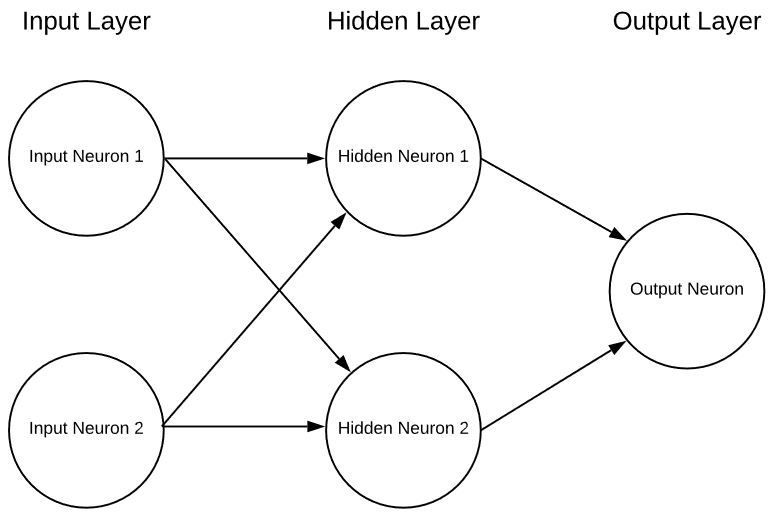 Se trata de una red neuronal extremadamente simplista con 2 entradas, una única capa oculta de neuronas y, por último, una única neurona de salida. Las redes neuronales pueden tener cualquier número de entradas, capas y cualquier número de neuronas en esas capas. Esta flexibilidad es el único problema serio de las redes neuronales. ¿Cómo sabe el diseñador de la red cuál es el número óptimo de capas y neuronas dentro de esas capas? Hay algunas pautas por las que empezar, pero la realidad es que todo es cuestión de ensayo y error. Actualmente se están llevando a cabo investigaciones muy prometedoras para ayudar en este sentido, pero apenas estamos empezando a descifrar esta parte.
¿Cómo se eligen los pesos y sesgos adecuados para cada neurona y cómo "aprende"?
Un gran tema para la próxima entrega.
Se trata de una red neuronal extremadamente simplista con 2 entradas, una única capa oculta de neuronas y, por último, una única neurona de salida. Las redes neuronales pueden tener cualquier número de entradas, capas y cualquier número de neuronas en esas capas. Esta flexibilidad es el único problema serio de las redes neuronales. ¿Cómo sabe el diseñador de la red cuál es el número óptimo de capas y neuronas dentro de esas capas? Hay algunas pautas por las que empezar, pero la realidad es que todo es cuestión de ensayo y error. Actualmente se están llevando a cabo investigaciones muy prometedoras para ayudar en este sentido, pero apenas estamos empezando a descifrar esta parte.
¿Cómo se eligen los pesos y sesgos adecuados para cada neurona y cómo "aprende"?
Un gran tema para la próxima entrega.
Esta neurona tiene 2 entradas.
Cada entrada se multiplica por el peso.
A continuación se suman las entradas ponderadas y se les añade un valor de sesgo.
Por último, el valor sin límites se pasa por una función de activación (sigmoidea, por ejemplo) para reducirlo a un rango predecible (de 0 a 1, por ejemplo).
He aquí un ejemplo de una neurona en acción:
Entrada 1 = 5, Entrada 2 = 8, W1 = 1 y W2 = .5, finalmente nuestro Bias es 3
Nuestra salida es la siguiente
Af( ( 5 * 1 ) + ( 8 * .5 ) + 3 )
Af( 12 ) = 0.999
Intentémoslo de nuevo con un conjunto diferente de entradas, pesos y sesgo:
Entrada 1 =-10, Entrada 2 = 10, W1 = 0,2, W2 = 0,1, Sesgo = 0,5
Salida = Af( (-10 + 0.2) + ( 2 X 0.1) + 0.5)
Salida = Af( -8.1 ) = 3.034
Una sola neurona por sí sola es esencialmente inútil aparte de como un ejercicio matemático interesante, pero si ponemos varias neuronas juntas en capas podemos tener una red neuronal en la forma de:
Se trata de una red neuronal extremadamente simplista con 2 entradas, una única capa oculta de neuronas y, por último, una única neurona de salida. Las redes neuronales pueden tener cualquier número de entradas, capas y cualquier número de neuronas en esas capas. Esta flexibilidad es el único problema serio de las redes neuronales. ¿Cómo sabe el diseñador de la red cuál es el número óptimo de capas y neuronas dentro de esas capas? Hay algunas pautas por las que empezar, pero la realidad es que todo es cuestión de ensayo y error. Actualmente se están llevando a cabo investigaciones muy prometedoras para ayudar en este sentido, pero apenas estamos empezando a descifrar esta parte.
¿Cómo se eligen los pesos y sesgos adecuados para cada neurona y cómo "aprende"?
Un gran tema para la próxima entrega.
Subscribe to the blog